Agrégations temporelles avec timescale
Auteur : Philippe Le Van - @plv@framapiaf.org
Date : 23 juin 2021
Introduction : qu'est-ce qu'un agrégation temporelle (ou downscale)
Un exemple d'agrégation temporelle consiste à faire une requête qui renvoie la moyenne des valeurs des données reçues toutes les 5mn.
Les paramètres d'une agrégation sont :
- la "fonction d'agrégation" : moyenne, médiane, max, min, count,...
- la largeur de l'agrégation (5mn, 15mn, 1h,...)
- la position temporelle de l'agrégation (à gauche de l'intervale, au milieu, à droite ?)
- quand on n'a pas de valeur dans l'intervale, que doit renvoyer la base (est-ce qu'on ne renvoie rien ou est-ce qu'on remplit les trous avec des valeurs null ?)
Dans tous les exemples suivants on considère :
- des données qui arrivent toutes les 15mn à partir de 10h
- une agrégation toutes les heures
Timescaledb est une extension postgresql qui ajoute des fonctions dites "timeseries" à postgres, notamment des fonctions d'agrégations temporelles.
Fonctionnement d'un time_bucket
Pour comprendre le fonctionnement de time_bucket, il faut commencer par l'utiliser sans faire de group by dessus.
un time_bucket simple
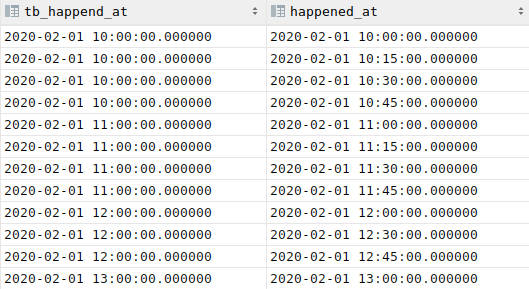
dans le cas standard, time_bucket prend une date en entrée et renvoie la date de l'agrégat dont la largeur est définie dans le 1er paramètre.
Dans l'exemple ci-dessous la largeur est de 1h. time_bucket saucissonne le temps en tranches : 00h00->01h00, 1h00->2h00, ... Quand une valeur de happend_at est dans une tranche, time_bucket renvoie la borne gauche de la tranche.
1 2 3 4 5 6 7 8 | |
Le résultat est :
Un time_bucket avec un offset
Dans l'exemple ci-dessus j'ai dit que les tranches étaient d'1h en commençant à minuit : 00h00->01h00, 1h00->2h00, ...
Ce minuit est un choix arbitraire de timescale. On peut changer ce choix avec le paramètre "offset" de time_bucket.
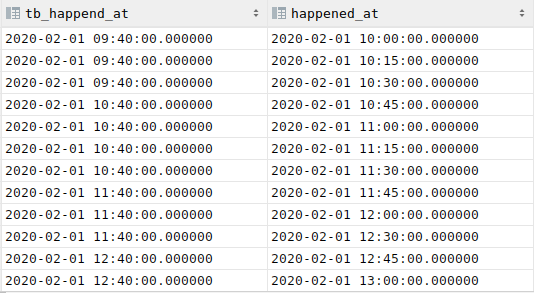
Dans l'exemple ci-dessous, on décide de décaler l'offset de 20mn à gauche. Timescale va du coup diviser le temps toujours en tranche d'1h, mais à partir de 23h40 la veille :
23h40->0h40, 0h40->1h40, 1h40->2h40, ...
et comme dans le cas simple, si une valeur est dans une des tranches, time_bucket renvoie la borne gauche de la tranche.
1 2 3 4 5 6 7 8 9 | |
Le résultat est le suivant :
Group by et agrégations
Group by sur un time_bucket : faire une agrégation simple (ou downscaling)
Le but des time_bucket est de pouvoir faire des group by dessus.
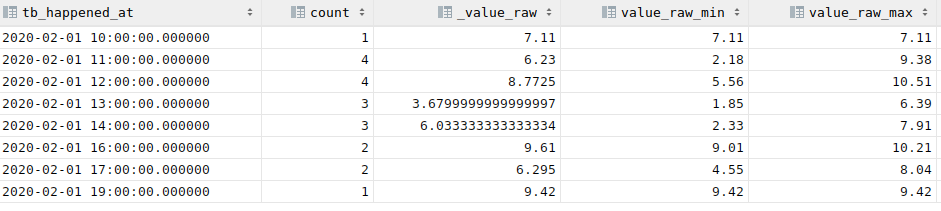
La valeur agrégée à 10h va contenir l'agrégation des valeurs (10h00, 10h15, 10h30, 10h45)
1 2 3 4 5 6 7 8 9 10 11 | |
Le résultat donne :
Group by sur un time_bucket avec gapfill: remplir les trous
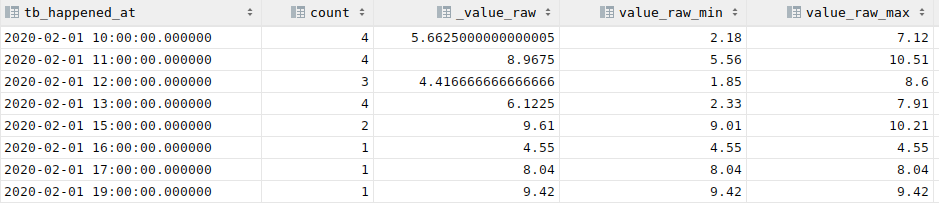
Dans l'exemple au-dessus, il y a des trous dans l'agrégation, simplement parce qu'il n'y a pas de données dans l'intervale.
Il est parfois pratique de remplir les trous. Pour ça, on peut remplacer time_bucket par time_bucket_gapfill (et ajouter les where qui vont bien)
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Le résultat est le suivant :
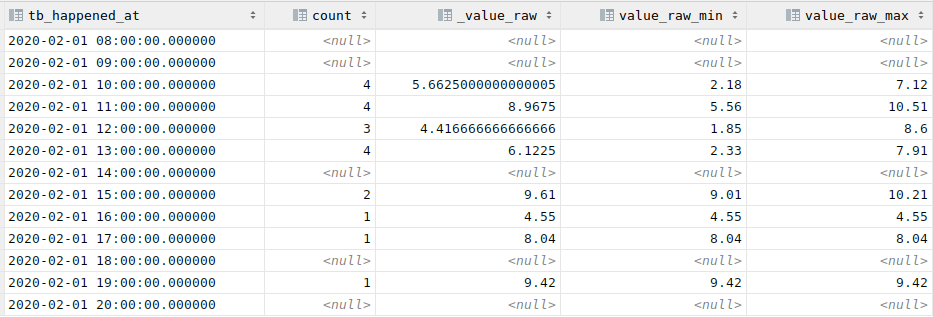
PS : il y a beaucoup de magie dans ce "gapfill". Je ne sais pas bien comment il arrive à remplir les trous alors qu'il n'a pas de valeur pour activer la fonction...
Agrégation borne droite (date de l'agrégat à gauche)
Pour un projet, on a eu besoin que l'heure de l'agrégat soit la borne de droite et non la borne de gauche.
La valeur agrégée à 10h va contenir l'agrégation des valeurs (9h15, 9h30, 9h45, 10h00).
Pour ça, il suffit d'ajouter 1h à la valeur de tb_happened_at.
Le soucis c'est que par défaut, time_bucket exclue la valeur droite de son intervale et inclue la valeur gauche. Pour une agrégation avec la borne à droite, il faut faire l'inverse : il faut inclue la borne de droite et exclure la borne de gauche. Pour ça on fait un hack horrible : on décale l'offset de 10µs à droite (comme ça on n'a plus la borne de gauche et on a la borne de droite), puis on décale la borne en retirant ces 10µs à tb_happend_at.
Je vous invite à lancer la requete sans le group_by pour bien comprendre comment ça marche.
1 2 3 4 5 6 7 8 9 10 11 12 | |
Le résultat est ici :